
Ένα νέο νευρωνικό δίκτυο που ανέπτυξε η Google μπορεί να υπολογίζει την ακριβή τοποθεσία μίας φωτογραφίας, χωρίς την ανάγκη geotags. Πρόκειται για ένα επίτευγμα της τεχνητής νοημοσύνης που θεωρείται πραγματικά εντυπωσιακό.
Το project έχει επικεφαλής τον computer vision specialist της Google, Tobias Reynard, και, όπως φαίνεται, το πρόγραμμα με τη βοήθεια της AI μπορεί να ξεπεράσει την ικανότητα ενός ανθρώπου να αναγνωρίζει την τοποθεσία μίας φωτογραφίας. Έχει επίσης δικό του αλγόριθμο που μπορεί να υπολογίζει ακόμη και την τοποθεσία φωτογραφιών που έχουν τραβηχθεί σε εσωτερικό χώρο!
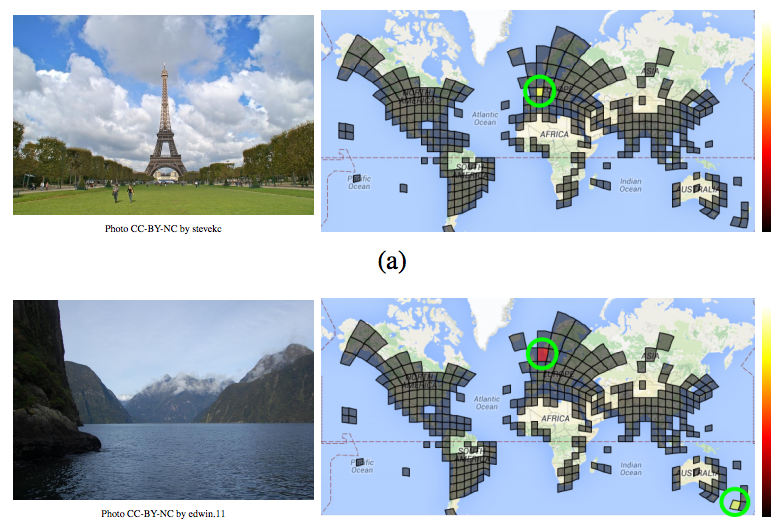
Η ομάδα δημιούργησε μία βάση δεδομένων 126 εκατομμυρίων φωτογραφιών με geolocations από το Web και χρησιμοποίησε τα data ώστε να προσδιορίσει πού έχει τραβηχθεί η κάθε μία. Χρησιμοποιώντας 91 εκατομμύρια από αυτές τις φωτό, “δίδαξε” ένα νευρωνικό δίκτυο ώστε να μπορεί να αναγνωρίζει την τοποθεσία μίας φωτογραφίας και το αποτέλεσμα ήταν πέραν του αναμενομένου.
Η τεχνητή νοημοσύνη της Google που ονομάζεται PlaNet πραγματοποίησε δοκιμές σε 2,3 εκατομμύρια εικόνες και υπολόγισε σωστά την πόλη προέλευσής στο 10,1%, τη χώρα στο 28,4%.από αυτές, ενώ όσον αφορά την ήπειρο είχε επιτυχία 48%.
Πρόκειται, όπως σημειώσαμε, για υψηλότερα σκορ από αυτά που ένας άνθρωπος μπορεί να επιτύχει και σίγουρα το μέλλον είναι άκρως υποσχόμενο γι’ αυτό το project, για το οποίο αναμένουμε να δούμε και τι πρακτικές εφαρμογές θα μπορούσε να έχει…

{kind=link}
τα σχόλια είναι κλειδωμένα.